– Chequeo de consistencia – compara los datos en la estructura del directorio con los bloques de datos en disco, y trata de arreglar inconsistencias.
– Uso de programas del sistema para sacar backup de los datos de disco a otro dispositivo de almacenamiento (disquete, cinta, etc).
– Recuperación de archivos perdidos o disco al recuperar datos desde el backup.
– Respaldo total vs respaldo incremental.
Esquema Abuelo-padre-hijo.
- D1….D4
- S1….S3
- M1….M5
- S1
- A1….
Otros esquemas de respaldo y recuperación
- Protección a nivel de disco: Múltiples copias de FAT; arreglo en caliente para detección y corrección de bloques malos.
- Duplexión.
- Disco espejo.
- Sistemas RAID: Redundant array of inexpensive/independent disks. Conjunto de drives que aparecen como uno solo. El nivel de redundancia depende del nivel RAID.
RAID 0

Data Stripping without parity (DSA). Datos copiados en distintos discos sin redundancia, datos en banda de discos sin paridad sin corrección de errores, no tolerancia a fallos, se aprovecha todo el disco.
RAID 1 (Espejo)

Mirrored Disk Array (MDA). Los datos son copiados en un arreglo de drives y cada drive tiene su backup espejo. Cuando se describen datos en una unidad, también se escriben con la otra. El disco redundante es una réplica exacta del disco de datos, por lo que se conoce también como disco espejo. Caro ya que necesitamos el doble de espacio que el necesario.
RAID 2 (Redundancia por código Hamming)

Datos copiados a nivel de bit en todos los drives. No usado. Este nivel cuenta con varios discos para bloques de redundancia y corrección de errores. La división es a nivel de bits, cada byte se graba con un bit cada uno de los discos y un bit de paridad en el noveno y el acceso es simultáneo a todas las unidades tanto en operaciones de escritura como lectura.
RAID 3 (bit de paridad intercalado)

Datos copiados a nivel de bit o byte en todos los drives excepto uno que es el drive de paridad. Lento escritura. Utiliza también un disco de protección de información separado para almacenar información de control codificada con lo que se logra una forma más eficaz de proporcionar redundancia de datos. Este control de información codificada o paridad proviene de los datos almacenadas en los discos y permite la reconstrucción de información en caso de fallas. Se requieren como mínimo 3 discos y se utiliza la capacidad de un disco para la información de control.
RAID 4 (Paridad a nivel de bloque)

Independient Disk Array (IDA) Similar al anterior pero a nivel de sectores, mejora rendimiento. En este nivel los bloques de datos pueden ser distribuidos a través de un grupo de discos para reducir el tiempo de transferencia y explotar toda la capacidad de transferencia de datos de la matriz de disco. El nivel 4 de Raid es preferible al nivel 2 de Raid para pequeños bloques de datos, porque en este nivel, los datos son distribuidos por sectores y no por bits.
RAID 5 (Paridad distribuida a nivel de bloque)

Datos escritos a nivel de sectores. Se incluyen códigos de corrección de error en todos los drives. Los datos y la paridad son guardados en los mismos discos por lo que conseguimos aumentar la velocidad de demanda, ya que cada disco puede satisfacer una demanda independiente de los demás. A diferencia del RAID 3, el RAID 5 guarda la paridad del dato dentro de los discos y no hace falta un disco para guardar dichas paridades.
RAID 6 (Redundancia dual)

Sistemas independientes de disco con integración de código de error mediante una doble paridad. Es esencialmente una extensión del RAID 5, para ello guarda, una segunda paridad. Este nivel proporciona muy buena integridad de los datos y repara diversos errores en los discos. Añade un nivel más de disco, resultando una organización con dos dimensiones de disco y una tercera que corresponde a los sectores de los discos la ventaja de este nivel consiste que no solamente se puede recuperar un error de entre dos discos, sino que es posible recuperar muchos errores de 3 discos. La operación de escritura es difícil debido a la necesidad de sincronizar todas las dimensiones.
RAID de nivel superior
- RAID 10: La información se distribuye en bloques como el RAID 0 y adicionalmente, cada disco se duplica como RAID 1, creando un segundo nivel de arreglo se conoce como “Strippng de arreglos duplicados”. Se requieren dos canales, dos discos para cada canal y se utilizan el 50% de la capacidad para información de control.
- RAID 30: ES ideal para aplicaciones no interactiva, tal como señales de gráfico e imágenes. Se conoce también como Stripping de arreglos de paridad dedicada. La información es distribuida a través de los discos, como en RAID 0 y utiliza paridad dedicada, como RAID 3, en un segmento canal, requiere mínimo 6 discos.
- RAID 50: Está diseñado para aplicaciones que requieren un almacenamiento altamente confiable una elevada tasa de lectura y un buen rendimiento en la transferencia de datos con un nivel de RAID 50, la información se reparte en los discos y se usa paridad distribuida, por eso se conoce como Stripping de arreglo de paridad distribuidas. Se requiere mínimo 6 discos.
RAID 10

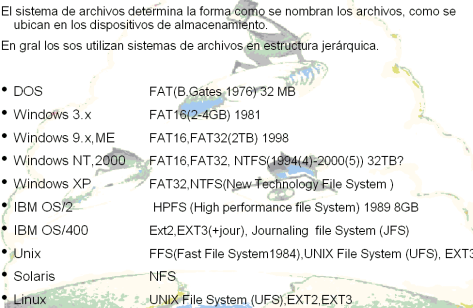
SISTEMAS DE ARCHIVOS DE ALGUNOS SOS
El sistema de archivos determina la forma como se nombran los archivos, como se ubican en los dispositivos de
TENDENCIAS EN SISTEMAS OPERATIVOS
– Las principales abstracciones de hoy día: procesos, hilos, sockets, y archivos no manejan adecuadamente los problemas de administración de la localidad, disponibilidad y tolerancia a fallos. Los sistemas operativos distribuidos pueden resolver estos problemas.
– Cualquier fragmento de código debe poder correr en cualquier parte.
– El sistema debe manejar localidad, replicación y migración de datos y operaciones.
– Los SO del futuro de3ben estar listos para internet, comercio electrónico, intranet/extranet, operaciones basadas en internet, servidores de correo electrónico, web, servicios web, etc.
– El sistema debe ser:
- Auto configurable.
- Autoajustable.
- Automonitoreable.
- Escalable.
- Confiable.
- Seguro.
- Robusto.
- Escalable (a nivel mundial).
- Tolerante a fallos.
- Persistente.
- Preparado para la red.
- Favorable a la movilidad.
- Extensible.
- Orientado a objetos.
- Orientado a GUI.
- Mayores longitudes de palabra.
- Ambientes multitarea.
- Reconocimiento automático de componentes.
- Autodiagnostico.
- RISC.
- Múltiples ambientes operativos.
- Múltiples idiomas.
- Kernel paginable.
- Interoperatividad.
- Procesamiento paralelo.
- Dispositivos ópticos multiescritura.
- Gestión de comunicaciones y bases de datos de Kernel.
- Configuración en caliente.
- Registro y seguimiento de operaciones, log, journal.
- Abstracción agresiva.
- Irrelevancia en el almacenamiento.
- Irrelevancia en ubicación.
- Vinculación justo a tiempo.
- Introspección.
- Gran semántica.
- Arquitecturas descentralizadas: Mejora relación precio beneficio PC- redes.
- Estándares.